How to Run OR Debug Map Reduce algorithm using eclipse IDE, without installing Hadoop & HDFS on Windows OS.
This guide is intended for anyone who is looking for an answer to any of the following questions:
- How do I create/run/debug a MapReduce project using Eclipse IDE?
- How do I Run MapReduce locally without installing Hadoop & HDFS?
- How do I run the same on windows OS?
Prerequisite:
- Eclipse.
- JDK Installed.
- Cygwin installed.
- Hadoop-jars (Download from here)
Problem statement:
In a Mobile banking application, Bank sent the Push notification using GCM to each customer and encouraged them to share their user experience about the app on a scale of 1-5 stars. If user gives rating below 3, Then will be asked for feedback about how to improve user experience.now, bank wants to perform statistical analysis on basis of this huge data collected.
Below are the logs excerpted from file,
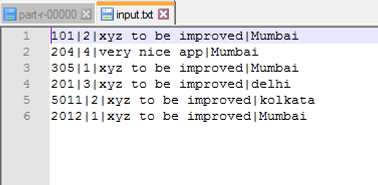
Above logs provides fair idea about customerID |User Rating | User Feedback | City.
Solution :
Let’s now try to understand how Map-Reduce works and how map-reduce can help here to process these logs.
Map-Reduce algorithm works in three modes,
- Standalone Mode.
- Pseudo Mode.
- Distributed Mode.
In this tutorial will understand how Map-Reduce works in Standalone mode without installing HDFS and hadoop.
Map-Reduce helps in processing large number of structured and unstructured data in parallel and across the different clusters.
As name indicates Map-Reduce program consists of two phases, Map phase and Reduce phase. Both the phases have an input and output as key/value pairs. Output key/value pair of Mapper goes as an input key/value pair to the Reducer. and developers can choose appropriate data models type according to the problem statement.all the keys should be unique.
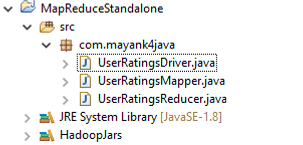
Step-I.
Create a simple java project as MapReduceStandalone and create package com.mayank4java in eclipse as shown below,
Step-II.
The Map function reads the input files as key/value pairs, processes each, and generates zero or more output key/value pairs.In the Map function we will filter out any unwanted fields or data from the input file and we will only take the data we are interested in to.
Let's write the Mapper code to process single record at a time from the input file. We will never write logic in Map-Reduce to deal with entire data set. The framework is responsible to convert the code to process entire data set by converting into desired key value pair.
Below is the Mapper code,
package com.mayank4java;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class UserRatingsMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable>
{
private final IntWritable count=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException
{
String line=value.toString();
StringTokenizer tokens=new StringTokenizer(line, "|");
tokens.nextToken();
IntWritable rating=new IntWritable(Integer.parseInt(tokens.nextToken()));
context.write(rating, count);
}
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
}
{
private final IntWritable count=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException
{
String line=value.toString();
StringTokenizer tokens=new StringTokenizer(line, "|");
tokens.nextToken();
IntWritable rating=new IntWritable(Integer.parseInt(tokens.nextToken()));
context.write(rating, count);
}
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
}
Step-III.
Next step is to write Reducer code. It Processes the output generated from all the Mappers and generates output in Key/Value pair. Will store the output of Reducer into the file system.Reducer internally performs three tasks that is Shuffling, Sorting and reducing.
Below is the Reducer code,
package com.mayank4java;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class UserRatingsReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>
{
@Override
public void reduce(final IntWritable key, final Iterable<IntWritable> values,
final Context context) throws IOException, InterruptedException {
int sum = 0;
Iterator<IntWritable> iterator = values.iterator();
{
@Override
public void reduce(final IntWritable key, final Iterable<IntWritable> values,
final Context context) throws IOException, InterruptedException {
int sum = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
IntWritable val=iterator.next();
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
IntWritable val=iterator.next();
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
Step-IV.
Next task is to write Driverclass. Where in we will configure Mapper,Reducer, Input/Output data type formats etc. Let's create UserRatingsDriver.java as shown below,
package com.mayank4java;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class UserRatingsDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.out.println("Usage: [input] [output]");
System.exit(-1);
}
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.out.println("Usage: [input] [output]");
System.exit(-1);
}
Job job = Job.getInstance(getConf());
job.setJobName("userrating");
job.setJarByClass(UserRatingsDriver.class);
job.setJobName("userrating");
job.setJarByClass(UserRatingsDriver.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(UserRatingsMapper.class);
job.setCombinerClass(UserRatingsReducer.class);
job.setReducerClass(UserRatingsReducer.class);
job.setCombinerClass(UserRatingsReducer.class);
job.setReducerClass(UserRatingsReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path inputFilePath = new Path(args[0]);
Path outputFilePath = new Path(args[1]);
Path outputFilePath = new Path(args[1]);
FileInputFormat.addInputPath(job, inputFilePath);
FileOutputFormat.setOutputPath(job, outputFilePath);
FileOutputFormat.setOutputPath(job, outputFilePath);
FileSystem fs = FileSystem.newInstance(getConf());
if (fs.exists(outputFilePath)) {
fs.delete(outputFilePath, true);
}
fs.delete(outputFilePath, true);
}
return job.waitForCompletion(true) ? 0: 1;
}
}
public static void main(String[] args) throws Exception {
UserRatingsDriver userRatingDriver = new UserRatingsDriver();
int res = ToolRunner.run(userRatingDriver, args);
System.exit(res);
}
}
UserRatingsDriver userRatingDriver = new UserRatingsDriver();
int res = ToolRunner.run(userRatingDriver, args);
System.exit(res);
}
}
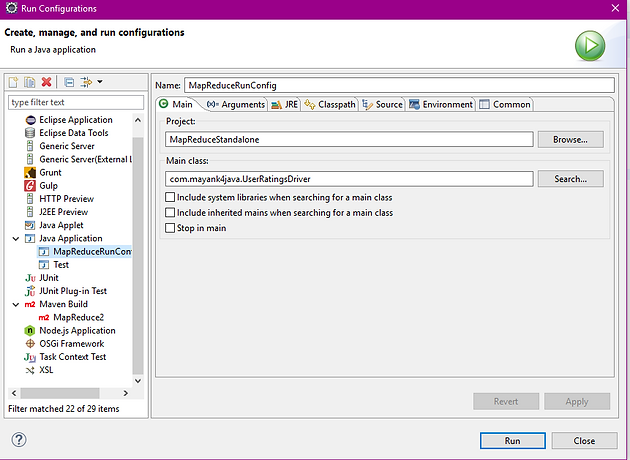
Step-V.
Create New Run configuration as MapReduceRunConfig by mapping Main class as UserRatingsDriver.java as shown below,
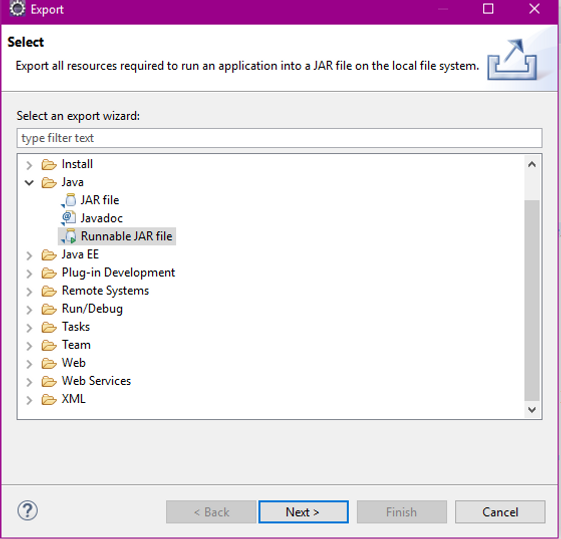

Step-VI.
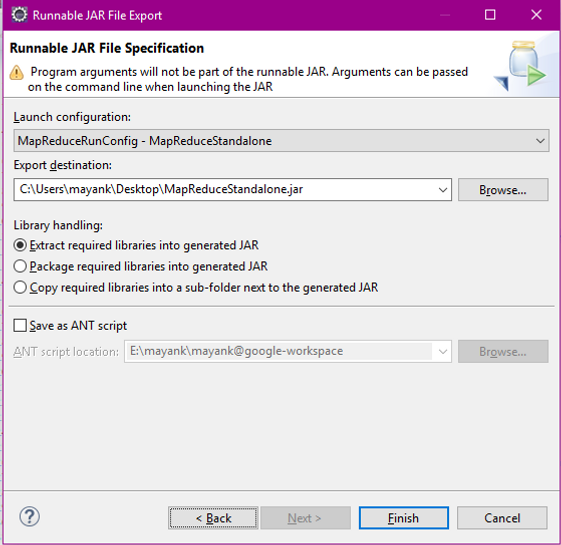
Export as a Runnable jar file .
Step-VII.
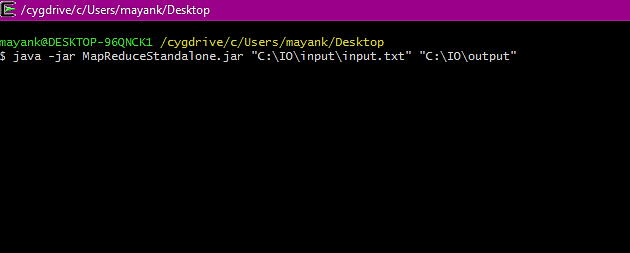
As UserRatingsDriver class takes path of the input file and output directory as command line arguments. So just open the CygWin terminal and run below command,
java -jar MapReduceStandalone.jar "C:\IO\input\input.txt" "C:\IO\output"
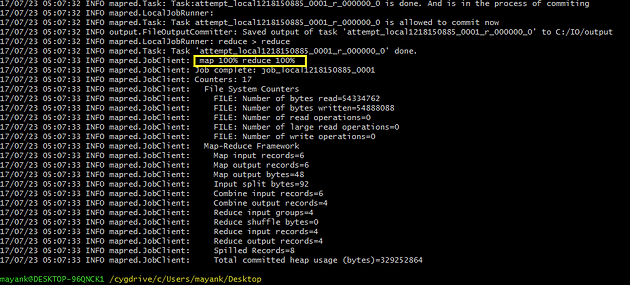
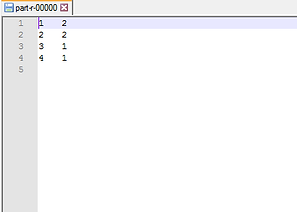
As you can see in above logs, Map-Reduce processed the data and stored the output into the file system. From the below file we can analyse that, There are 2-2 customers with the ratings as 1* and 2* respectively.
That is it folks!
Hope this post helped you.Also don't forget to share and leave your comments below.


Nice
ReplyDelete